Thank you QIP audience! On Tuesday, I gave a presentation on this paper
Phys. Rev. A 95, 042306 (2017)
https://arxiv.org/abs/1612.02689
I had some great questions, but in retrospect don’t think my answers were the best. Many questions focused on how to interpret results showing that random circuits improve on purely unitary circuits. I often get this question and so tried to pre-empt it in the middle of my talk, but clearly failed to convey my point. I am still getting this question every coffee break, so let me try again. Another interesting point is how the efficiency of an optimal compiler scales with the number of qubits (see Part 2). In what follows I have to credit Andrew Doherty, Robin Blume-Kohout, Scott Aaronson and Adam Bouland, for their insights and questions. Thanks!
First, let’s recap. The setting is that we have some gate set 





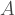

The main result I presented was that we can find a probability distribution of circuits 

is 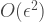
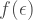
But what the heck is going on here!? Surely, each individual run of the compiler gives a particular circuit 
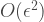
Each time we use a random compiler we get some circuit 
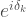


For each subcircuit compiling is reasonable (e.g. it acts nontrivially on only a few qubits) but the whole computation acts on too many qubits to optimally compile or even compute the matrix representation. Then using random compiling we implement some sequence

with some probability
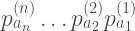
OK, now let’s see what happens with the coherent noise terms. For the 

so the whole computation we implement is

We can conjugate the noise terms through the circuits. For instance,

where
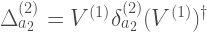
Since norms are unitarily invariant we still have

Repeating this conjugation process we can collect all the coherent noise terms together

Using that the noise terms are small, we can use

where

Using the triangle inequality one has

But this noise term could be much much smaller than this bound implies. Indeed, one would only get close to equality when the noise terms coherently add up. In some sense, our circuits must conspire to align their coherent noise terms to all point in the same direction. Conversely, one might find that the coherent noise terms cancel out, and one could possibly even have that 
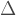

Furthermore, we are summing a series of such terms (sampled independently). A sum of independent random variables are going to convergence (via a central limit theorem) to some Gaussian distribution that is centred around the mean (which is zero). Of course, there will be some variance about the mean, but this will be 

More in part 2
