This post is a light summary of a project just published in Physical Review Letters. I am very pleased that this work got selected as an editor’s suggestion and that the legendary Dominic Berry was commissioned to write a Physics view-point. His viewpoint really is a superb summary and you should go read it now, then come back here!
on how best to simulate time evolution using a quantum computer, which can also be helpful with other tasks like finding the ground state energy of a Hamiltonian. The standard method is to Trotterize the dynamics, and in some situations this works quite well, but it struggles with Hamiltonians containing a large number of terms.
If a Hamiltonian has L terms then even the best known Trotter methods have a gate count scaling quadratically with L. This is especially problematic in molecular systems because an N electron/qubit system will have about N^4 terms in the Hamiltonians, so L^8 gates in the Trotterized approach. Since systems beyond the reach of classical computers have N>40, the numbers quickly become horrifying.
My new work proposes a protocol with no explicit L dependence in the gate count, so it performs much better for Hamiltonians with many, many terms. The key idea is to use randomness.
Before getting to the new ideas, let’s recap Trotterization using some simple pictures. In Trotterization, we divide the evolution into r Trotter steps. In the simplest version of Trotter, each step contains one gate for each term in the Hamiltonian as follows.

Each gate is a coloured block with the width indicating the duration of the pulse. The width of the blocks are proportional to the corresponding coefficients in the Hamiltonian. In the standard cost model, each of these blocks has unit cost, independent of the duration of the gate, so the above sequence has cost 5. Next, we repeat this r times to obtain a sequence illustrated by:

where here we have taken 10 Trotter steps. There are 5 gates per step and so 50 gates in the whole sequence. The black ticks are just to guide the eyes to the divisions between each step.
How to do better? The main idea is to use random compiling. Both me and Matt Hasting showed a couple of years ago that randomisation can be very useful in compiling quantum circuits. If your interested in this more general problem, I gave a talk at QIP at Delft. Childs, Ostrander, and Su have a paper where they suggest randomly permuting gates within each Trotter step, so for a particular sample you might get a sequence like

This does lead to improved performance but does not escape the L^2 dependence of the gate count, so still isn’t especially suited to Hamiltonians with very many terms.
In my paper, I proposed that we instead choose all the gates in the sequence independently (i.i.d) at random, with each block having the same width/duration. So every gate is of the form

where the width 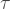

The colour refers to which 
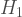
There are two effects at work here. First, we see that in the original Trotter there were a lot of weak gates (yellow, green and purple) that were repeated in every step. One of the main savings is that these are consolidated. Second, the sequence is random and so any coherent noise effects are washed out into less harmful stochastic noise. This is a very subtle point that I’ve blogged on previously, so I won’t labour the point again other than to stress that the protocol only works if a different random sequence is used for every run of the quantum computer.
Remarkably, one finds the number of gates required is independent of the number of terms in the Hamiltonian! This is proved by Taylor expanding and careful bounding of errors, much like the proofs for standard Trotter. One difference is that instead of Taylor expanding a unitary we perform a Taylor expansion of an exponentiated Lindblad operator.
For technical details, you should see the paper. To wrap up here, I just want to add that the above random protocol (which I call qDRIFT) is very simple and there is plently of scope for more sophisticated ideas exploiting the same effects. Right away one can see that there is some waste in the above gate sequence; whenever you see subsequent gates of the same colour, they can be merged into a single gate. Applying such a merge strategy to the above, one would have the sequence:

which has only 16 gates!
