If a quantum device would ideally prepare a state 

For many people, the gold standard is to use the fidelity. This is defined as

One of the main goals of this blog post is to explain why the fidelity is a terrible, terrible error metric. You should be using the “trace norm distance”. I will not appeal to mathematical beauty — though trace norm wins on these grounds also — but simply to what is experimentally and observationally meaningful. What do I mean by this? We never observe quantum states. We observe measurement results. Ultimately, we care that the observed statistics of experiments is a good approximation of the exact, target statistics. In particular, every measurement outcome is governed by a projector 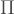
![\epsilon_\Pi = | \mathrm{Tr} [ \Pi \rho ] - \langle \psi \vert \Pi \vert \psi \rangle |](https://s0.wp.com/latex.php?latex=%5Cepsilon_%5CPi+%3D+%7C+%5Cmathrm%7BTr%7D+%5B+%5CPi+%5Crho+%5D+-+%5Clangle+%5Cpsi+%5Cvert+%5CPi+%5Cvert+%5Cpsi+%5Crangle+%7C++&bg=ffffff&fg=404040&s=2&c=20201002)
Error in outcome probabilities is the only physically meaningful kind of error. Anything else is an abstraction. The above error depends on the measurement we perform, so to get a single number we need to consider either the average or maximum over all possible projectors.
The second goal of this post is to convince you that randomness is really, super useful! This will link into the fidelity vs trace norm story. Several of my papers use randomness in a subtle way to outperform deterministic protocols (see here, here and most recently here). I’ve also written another blog posts on the subject (here). Nevertheless, I still find many people are wary of randomness. Consider a protocol for approximating 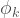

where
so our measure of error must depend on the averaged density matrix. Even though we might know after the event which pure state we prepared, the measurement statistics are entirely governed by the density matrix that averages over the ensemble of pure states. When I toss a coin, I know after the event with probability 100% whether it is heads or tails, but this does not prevent it from being an excellent 50/50 (pseudo) random number generator. Say I want to build a random number generator with a 25/75 split of different outcomes. I could toss a coin once: if I get heads then I output heads; otherwise I toss a second time and output the second toss result. This clearly does the job. We do not hear people object, “ah ha but after the first toss, it is now more likely to give tails so you algorithm is broken”. Similarly, quantum computers are random number generators and are allowed a “first coin toss” that determines what they do next.
![\sum_k p_k \langle \phi_k \vert \Pi \vert \phi_k \rangle = \mathrm{Tr}[ \Pi \rho ]](https://s0.wp.com/latex.php?latex=%5Csum_k++p_k+%5Clangle+%5Cphi_k++%5Cvert+%5CPi+%5Cvert+%5Cphi_k++%5Crangle+%3D+%5Cmathrm%7BTr%7D%5B+%5CPi+%5Crho+%5D+&bg=ffffff&fg=404040&s=1&c=20201002)
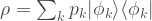
Let’s thinking about the simplest possible example; a single-qubit. Imagine the ideal, or target state, is 




Performing a measurement in the X-Z plane, we get the following measurement statistics.

We have three different lines for three states that all have the same fidelity, but the measurements errors behave very differently. Two things jump out.
Firstly, the fidelity is not a reliable measure of measurement error. For the pure states, in the worst case, the measurement error is 20 times higher than the error as quantified by fidelity. Actually, for almost all measurement angles the fidelity is considerably less than the measurement error for the pure states. Just about the only thing fidelity tells you is that there is one measurement (e.g. with 
Secondly, the plot highlights how the mixed state performs considerably better than the pure states with the same fidelity! Clearly, we should choose the preparation of the mixed state over either of the pure states. For each pure state, there are very small windows where the measurement error is less than for the mixed state. But when you perform a quantum computation you will not have prior access to a plot like this to help you decide what states to prepare. Rather, you need to design your computation to provide a promise that if your error is 
Now we can see that the “right” metric for measuring errors should be something like:
Nothing could be more grounded in experiments. This is precisely the trace norm (also called the 1-norm) measure of error. Though it needs a bit of manipulation to gets into it’s most recognisable form. One might initially worry that the optimisation over projections is tricky to compute, but it is not! We rearrange as follows
![\delta = \mathrm{max}_{\Pi} | \mathrm{Tr} [ \Pi \rho ] - \langle \psi \vert \Pi \vert \psi \rangle |](https://s0.wp.com/latex.php?latex=%5Cdelta+%3D+++%5Cmathrm%7Bmax%7D_%7B%5CPi%7D+%7C+%5Cmathrm%7BTr%7D+%5B+%5CPi+%5Crho+%5D+-+%5Clangle+%5Cpsi+%5Cvert+%5CPi+%5Cvert+%5Cpsi+%5Crangle+%7C+&bg=ffffff&fg=404040&s=2&c=20201002)
![\delta = \mathrm{max}_{\Pi} | \mathrm{Tr} [ \Pi (\rho- \vert \psi \rangle\langle \psi \vert) ] |](https://s0.wp.com/latex.php?latex=%5Cdelta+%3D+++%5Cmathrm%7Bmax%7D_%7B%5CPi%7D+%7C+%5Cmathrm%7BTr%7D+%5B+%5CPi+%28%5Crho-+%5Cvert+%5Cpsi+%5Crangle%5Clangle+%5Cpsi+%5Cvert%29+%5D++%7C+&bg=ffffff&fg=404040&s=2&c=20201002)
let
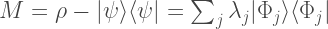
where we have given the eigenvalue/vector decomposition of this operator. The eigenvalues will be real numbers because 
It takes a little bit of thinking to realise that the maximum is achieved by a projection onto the subspace with positive eigenvalues
Because,
If we calculated this 
![\delta = \mathrm{max}_{\Pi} | \mathrm{Tr} [ \Pi M ] = \sum_{j : \lambda_j > 0} \lambda_j](https://s0.wp.com/latex.php?latex=%5Cdelta+%3D+++%5Cmathrm%7Bmax%7D_%7B%5CPi%7D+%7C+%5Cmathrm%7BTr%7D+%5B+%5CPi+M+%5D+%3D+%5Csum_%7Bj+%3A+%5Clambda_j+%3E+0%7D+%5Clambda_j++++&bg=ffffff&fg=404040&s=2&c=20201002)

We have just been talking about measurement errors, but have actually derived the trace norm error. Let us connect this to the usual mathematical way of introducing the trace norm. For an operator 
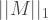
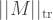
Hopefully, the reader can see that this is exactly what we have found above. In other words, we have the equivalence
![\frac{1}{2} || \rho -\sigma ||_{\mathrm{tr}} = \mathrm{max}_{\Pi} | \mathrm{Tr} [ \Pi ( \rho -\sigma) ]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D+%7C%7C+%5Crho+-%5Csigma+%7C%7C_%7B%5Cmathrm%7Btr%7D%7D+%3D+%5Cmathrm%7Bmax%7D_%7B%5CPi%7D+%7C+%5Cmathrm%7BTr%7D+%5B+%5CPi+%28+%5Crho+-%5Csigma%29+%5D+&bg=ffffff&fg=404040&s=2&c=20201002)

Note that we need the density matrix to evaluate this error metric. If we have a simulation that works with pure states, and we perform statistic sampling over some probability distribution to find the average trace norm error
then this will massively over estimated the true error of the density matrix


I hope this convinces you all to use the trace norm in future error quantification.
I want to finish by tying this back into my recent preprint:
arXiv1811.08017
That preprint looks not at state preparation but the synthesis of a unitary. There I make use of the diamond norm distance for quantum channels. The reason for using this is essentially the same as above. If we have a channel that has error

One thought on “The folly of fidelity and how I learned to love randomness”